Четвертая лекция курса по архитектуре клиент-серверных android-приложений, в которой мы поговорим о том, что такое Clean Architecture и как реализовать чистую архитектуру в андроид. Также познакомимся с библиотекой Google Agera, которая реализует парадигму реактивного функционального программирования на Android.
Чтобы более тесно на практике познакомиться с чистой архитектурой и архитектурными компонентами, записывайтесь на продвинутый курс по разработке приложения «Чат-мессенжер»
- Введение
- Clean Architecture
- Бизнес-объекты
- Сценарии взаимодействия
- Слой представления
- Фреймворки
- Clean Architecture Android
- Слой данных
- Слой бизнес-логики
- Слой представления
- Пример приложения
- Дополнительно – Google Agera
- Практика
- Практика 2
- Ссылки и полезные ресурсы
- Продолжение:
- Лекция 5 по архитектуре андроид приложения. Паттерн MVP
Введение
В рамках первого занятия были выделены 2 основные задачи, которые нужно решать при разработке клиент-серверных приложений. Напомним, какие это задачи:
- Реализация клиент-серверного взаимодействия.
- Обеспечение возможности тестирования классов, содержащих бизнес-логику приложения.
На первых трех занятиях мы разбирали различные способы для решения первой задачи, и теперь мы знаем большое количество этих способов: лоадеры, сервисы, RxJava и другие.
Но вы не могли не заметить, что, хоть наш код и стал корректнее решать задачу обеспечения клиент-серверного взаимодействия, но при этом мы совершенно не приблизились к решению второй задачи. Мы все также писали почти весь код в Activity, поэтому о какой-то модульности и архитектуре говорить не приходится. Так что теперь настала пора исправить сложившуюся ситуацию и с помощью знаний, полученных в предыдущих лекциях, начать изучать способы построения архитектуры приложения и написания тестов.
Давайте еще раз конкретизируем задачи, которые нам необходимо решить. Во-первых, код должен быть чище и понятнее. Когда вся логика серверных запросов, логика приложения, обработка взаимодействия с пользователем и отображение данных находятся в одной Activity, становится весьма тяжело понимать и поддерживать такой код. Поэтому нужно разделять такие Activity на классы по логическим блокам: к примеру, класс для работы с жизненным циклом, класс для отображения данных, класс, содержащий логику приложения, и так далее.
Во-вторых, приложение должно быть модульным. На самом деле в этом и заключается суть всех паттернов, которые мы будем рассматривать дальше, – в правильных способах разбиения приложения на модули. Эта задача очень сильно пересекается с первой задачей, поэтому дополнительных пояснений тут не требуется. Единственное, что нужно сказать, это то, что наиболее важные с точки зрения логики модули должны быть обязательно протестированы.
И в-третьих, как и было сказано на первом занятии, мы должны использовать такую архитектуру, которая позволяла бы менять окружение и тестировать модули в разных условиях. Здесь в первую очередь речь идет про принцип Dependency Injection.
Так что же с архитектурой? В этом вопросе у нас все достаточно комфортно. Сейчас идет 2017-ый год, и лучшие умы человечества уже давно продумали различные варианты построения архитектур для сложных систем. Более того, приложения для Android – это не слишком сложная система, поэтому у нас вообще не должно возникнуть никаких проблем.
Разумеется, мы можем пытаться придумать свои варианты архитектуры приложений, и это даже может получиться весьма неплохо, но зачем, если есть готовые варианты?
И снова возвращаемся к первому занятию. В нем было сказано, что основой для бурного развития исследования архитектуры клиент-серверных Android-приложений стала статья Фернандо Цехаса, “Architecting Android… The Clean Way?”, которая в свою очередь является переложением подхода “The Clean Architecture” от Роберта Мартина. Именно поэтому для нас логично рассмотреть эти два первоисточника, чтобы двигаться дальше.
Clean Architecture
Существует достаточно много подходов для построения сложных систем с хорошей архитектурой. Несмотря на небольшие различия этих подходов, у них много общего. Разумеется, они все задают способы разбиения приложения на отдельные модули. При этом в каждой системе как минимум есть модули, содержащие бизнес-логику приложения, и модули для отображения данных. И каждый подход в итоге позволяет построить систему, которая удовлетворяет следующим принципам:
- Архитектура должна быть независима от различных фреймворков. Разумеется, в современном мире мы не можем обходиться без каких-то библиотек, которые позволяют решать задачи намного быстрее и чаще эффективнее, чем это сделали бы мы в случае самостоятельной реализации. Но здесь важно понимать, что библиотека должна встраиваться в вашу архитектуру, а не архитектура должна подстраиваться под выбранную библиотеку. При использовании библиотеки, которая вынуждает вас переделывать архитектуру приложения, вы всегда будете сталкиваться с определенными ограничениями этой библиотеки и не сможете перестраивать архитектуру нужным вам образом. Нужно использовать библиотеки только в качестве вспомогательных инструментов.
- Система должна быть протестирована. При этом вы должны иметь возможность тестировать как модули системы по отдельности, так и тестировать взаимодействие этих модулей между собой и интеграцию их в системе. Кроме того необходимо тестировать систему без UI, реального сервера и работы с базой данных, то есть архитектура должна быть независима от окружения.
- Из предыдущих пунктов плавно вытекают и следующие принципы, которые говорят о том, что ваше приложение должно быть независимо от всего: от интерфейса пользователя, от работы с базой данных, от работы сервера и от других элементов окружения. Независимость архитектуры от окружения очень важна, так как это позволяет менять различные компоненты окружения без изменения самой архитектуры. Что подразумевается под изменением компонентов архитектуры? Это может быть изменение в выборе базы данных (или же вообще отказ от нее) или же изменение в UI-части приложения (к примеру, нужно изменить внешний вид экрана). Если для внесения таких изменений требует от вас изменения архитектуры, то, возможно, вам стоит пересмотреть архитектуру.
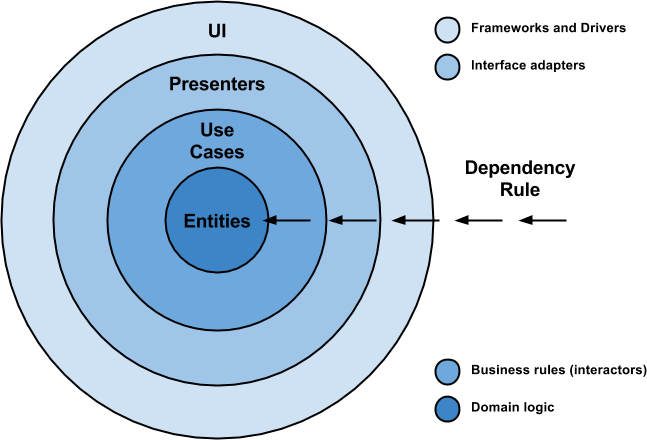
Для построения архитектуры системы предлагается рассмотреть следующую схему, где каждая концентрическая окружность является определенным компонентом системы:
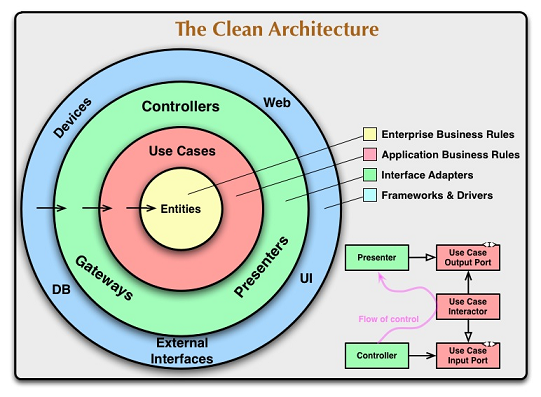
Как видно из схемы, система состоит из бизнес-объектов, объектов для управления данными и бизнес-логикой, из слоя представления и слоя высокоуровневых фреймворков. Можно сказать, что в общем случае это все такое же разбиение на представление данных и логику работы с ними.
Такое разделение системы на слои является весьма логичным и понятным. И пока оно не привносит ничего нового. Главным является правило зависимостей – ни один внутренний слой не должен знать ничего о внешнем. Именно это и позволяет строить независимую архитектуру, принципы которой были описаны выше.
Рассмотрим элементы системы более детально, чтобы понять, в чем заключается роль каждого элемента и как он должен взаимодействовать с другими элементами системы.
Бизнес-объекты
С точки зрения работы с системой в итоге мы всегда работаем с определенными сущностями, которые определяются требованиями системы. По сути бизнес-объекты – это классы моделей с определенными методами или же набор каких-то структур данных. Эти классы отвечают логике вашего приложения, и они должны определять самые общие правила поведения.
Поскольку это самый внутренний слой, то он будет меняться только в крайнем случае, когда вы решите изменить саму суть системы. И, разумеется, он останется нетронутым, когда будет меняться, к примеру, способ работы с данными или интерфейс пользователя.
Сценарии взаимодействия
Этот слой содержит реализацию основных методов для работы системы и организует работу с данными и бизнес-объектами. Он использует бизнес-объекты и их логику для того, чтобы выполнить свои задачи. Этот слой можно рассматривать как некоторый посредник между бизнес-объектами и непосредственно слоем представления данных (такое определение немного условно, так как по правилу зависимостей этот посредник не должен знать ничего о слое представления).
Разумеется, в силу правила зависимостей этот слой также не будет меняться при изменении какого-то из элементов окружения. И изменения на этом слое в свою очередь не будут затрагивать бизнес-объекты.
Слой представления
На этом слое осуществляется преобразование данных из формата, который используют бизнес-объекты или сценарии взаимодействия, в формат, необходимый для работы системы. Под работой системы в данном случае подразумевается передача данных для отображения пользователю или другой службе.
На этом слое реализуются такие архитектурные паттерны как Model-View-Controller или Model-View-Presenter. К примеру, Controller может передавать данные в сценарии взаимодействия, получать результат и передавать его для отображения во View.
Фреймворки
Изначально мы говорили, что система не должна зависеть ни от каких фреймворков. Именно поэтому слой фреймворков на схеме является самым внешним. Поскольку именно на этом уровне пропадает вся абстракция, и мы используем конкретные средства для решения определенных задач. Под конкретными средствами здесь подразумевается база данных, фреймворк для UI и другие службы.
Поскольку мы соблюдаем правило зависимостей, внутренние слои ничего не знают о конкретных используемых фреймворках, что позволяет легко изменить любой из них без изменения внутренних слоев.
В описанной схеме указано 4 слоя, и этого достаточно для большинства систем. Но, разумеется, при необходимости эту систему можно масштабировать и увеличивать количество слоев. Самое главное при этом – сохранять правило зависимостей.
Использование такого подхода позволяет создать архитектуру, принципы которой были описаны в начале раздела. В силу правила зависимостей мы получаем соответствие принципам 1 и 3, а такое разбиение системы на модули позволяет тестировать ее на разных уровнях.
Однако нужно понимать, что это теоретическое изложение, которое является достаточно общим и должно удовлетворять любой системе. На практике всегда нужно адаптировать архитектуру под конкретную задачу или систему. В нашем случае такой задачей являются клиент-серверные Android-приложения, поэтому перейдем к тому, как применить рассмотренные принципы к их архитектуре.
Clean Architecture Android
Нужно сказать, что архитектура Android-приложений обычно не бывает слишком сложной, поэтому, возможно, схему из Clean Architecture можно упростить без потери качества. И эту схему в любом случае нужно как-то адаптировать для конкретного использования в Android.
Такая адаптация была изложена в статье Фернандо Цехаса “Architecting Android… The clean way?”, которую мы и разберем детально.
Наиболее критичной с точки зрения тестирования приложения является бизнес-логика или бизнес-правила, определяющие суть работы приложения. И они должны быть в первую очередь независимы от других элементов и протестированы.
Чтобы достичь независимости и возможности тестирования, предлагается разбить приложение на 3 ключевых слоя:
- Слой данных (Data Layer)
- Слой бизнес-логики (Domain Layer)
- Слой представления (Presentation Layer)
При этом чтобы обеспечить максимальную независимость этих слоев, на каждом из них используется своя модель данных, которая конвертируется при взаимодействии между слоями.
Схема этих слоев выглядит следующим образом:
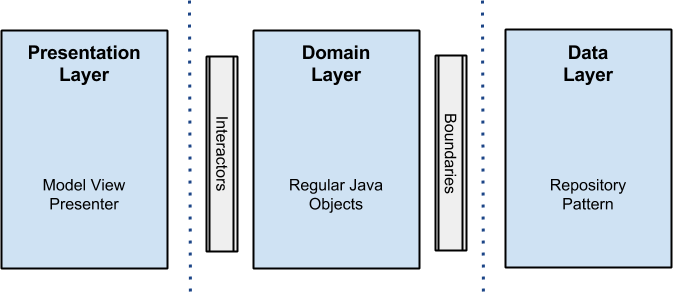
Основная идея всех архитектурных паттернов сохраняется – мы разбиваем код на модули на несколько слоев, среди которых обязательно есть слой, содержащий логику приложения, и слой, отвечающий за представление данных и работу с UI.
В предложенном варианте от Цехаса к этим двум основным слоям добавляется слой для работы с данными. Это позволяет упростить клиент-серверное взаимодействие и избавляет бизнес-логику приложения от необходимости работать с получением данных из различных источников.
Рассмотрим указанные слои подробнее.
Слой данных
Данный слой отвечает в первую очередь за получение данных из различных источников и их кэширование. Он реализуется за счет паттерна Repository, и его общую схему можно представить следующим образом:
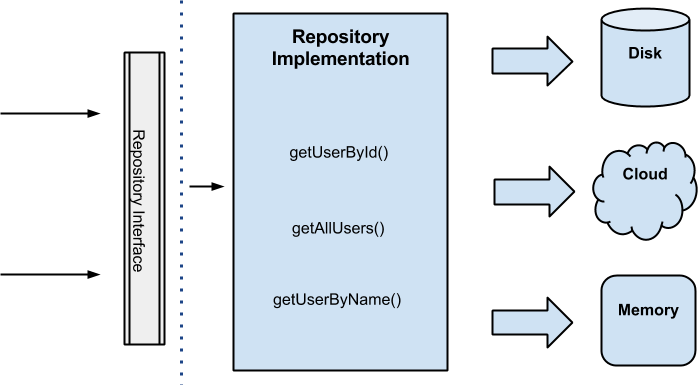
К примеру, когда необходимо получить какого-то пользователя по имени, реализация репозитория проверяет наличие этого пользователя в локальном хранилище, при отсутствии сохраненного пользователя она отправляет запрос на сервер и получает ответ, который сохраняется в локальное хранилище и возвращается. Или, к примеру, репозиторий может всегда обращаться к серверу, а уже в случае ошибки возвращать сохраненный результат.
Существует несколько плюсов от использования такого подхода. Во-первых, другие слои, которые запрашивают данные, не знают о том, откуда эти данные приходят. Более того, им не нужно этого знать, так как это усложняет логику работы и модуль берет на себя лишнюю ответственность. Во-вторых, слой данных в таком случае выступает единственным источником информации, что, как обсуждалось ранее, очень удобно.
Слой бизнес-логики
На слое бизнес-логики содержится, как ни странно, вся бизнес-логика приложения. Этот слой является неким объединением слоев сценариев взаимодействия и бизнес-логики в оригинальной “чистой” архитектуре. Именно к этому слою обращается слои представления для выполнения запросов и получения данных.
Фернандо Цехас предлагает реализовывать слой бизнес-логики в виде Java-модуля, который не содержит никаких зависимостей от Android-классов. И это хороший подход, так как для реализации бизнес-логики нам нужны только классы моделей и стандартные средства языка Java. Более того, такой подход позволит легко тестировать этот слой с помощью обычных тестов на JUnit, что очень удобно. В таком случае иногда не будет возможности выполнить какой-либо метод или использовать некоторые классы из других слоев. Поэтому для взаимодействия с этим слоем используются интерфейсы.
Слой представления
И, разумеется, приложение – это в первую очередь взаимодействие с пользователем. Поэтому нам нужен специальный слой, который будет отвечать за логику отображения данных на экране, за взаимодействие с пользователем и за другие процессы, связанные с UI. Этот слой не должен содержать логику приложения, не связанную с UI.
Именно этот слой привязывается к экранам и помогает организовать взаимодействие со слоем бизнес-логики и работу с данными. Этот слой может быть реализован с использованием любого предпочитаемого паттерна, к примеру, MVC, MVP, MVVM и других.
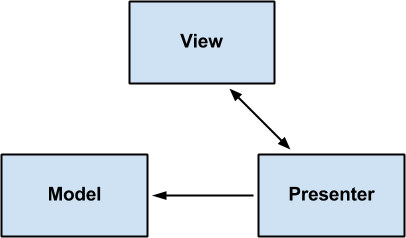
Конечно, наиболее часто используется паттерн MVP, который мы и будем рассматривать дальше. Подробнее его мы рассмотрим далее, а пока можно сказать, что это достаточно простой паттерн, который позволит нам разделить экран на UI-часть (View), на логику работы с UI (Presenter) и объекты для взаимодействия с UI (Model). В общем виде этот паттерн выглядит следующим образом:
И, разумеется, при разбиении приложения на такие слои нельзя забывать о главном правиле из “чистой” архитектуры – правиле зависимостей:
Теперь мы понимаем, как разбить приложение на модули и сделать эти модули относительно независимыми друг от друга, но нужно прояснить еще три вопроса, которые у нас постоянно возникают при построении архитектуры клиент-серверного приложения.
Во-первых, это вопрос про тестирование. Да, мы сказали, что, если мы строим приложение в виде независимых модулей, то их легко тестировать. Но как именно осуществляется это тестирование на практике? Вопросы тестирования мы будем разбирать в последующих лекциях, но пока приблизительно рассмотрим этот вопрос.
Очевидно, что самый важный слой с точки зрения тестирования – это слой бизнес-логики. А так как мы используем его в виде обычного Java-модуля, то тестировать его очень просто. Для этого достаточно стандартного фреймворка JUnit и, возможно, Mockito. Здесь нет проблем, специфичных для системы Android.
Слой данных также тестируются с помощью Unit-тестов на JUnit, но это уже требует определенных усилий, так как этот модуль содержит зависимости от классов Android. К примеру, для тестирования этого слоя можно дополнительно использовать фреймворк Robolectric.
И последний слой, слой представления, не содержит критичной логики, зато содержит много UI-элементов, которые также должны быть протестированы. Для этого можно воспользоваться специальными фреймворками, которые позволяют проводить интеграционное и UI-тестирование приложений, к примеру, Espresso.
Второй вопрос связан с обработкой ошибок. Ошибки в такой схеме могут возникать на любом уровне, но больше всего нас интересуют ошибки сервера, которые возникают на уровне данных. Здесь есть несколько возможных решений:
- В случае ошибки при получении данных можно достать данные из локального хранилища. Достаточно часто такая политика вполне оправдана, но при этом все равно стоит как-то уведомлять пользователя о произошедшей ошибке.
- Передавать ошибку через механизм обратного вызова. При получении ошибки в слое данных слой бизнес-логики может выполнить ее первичную обработку и передать ее слою представления, который и отобразит ошибку пользователю. Этот подход можно использовать и в сочетании с первым вариантом.
И последний открытый вопрос – это вопрос об управлении жизненным циклом. Поскольку слой данных никак не относится к проблемам пересоздания Activity и другим проблемам жизненного цикла, а слой бизнес-логики вообще не знает ничего о системе Android, то очевидно, что обработкой жизненного цикла должен заниматься уровень представления. К примеру, хорошим вариантом будет передача в Presenter делегата для управления жизненным циклом, что и будет использоваться далее. Но, разумеется, здесь можно использовать любой из способов, которые были рассмотрены на первой лекции.
Пример приложения
Мы рассмотрели теоретическое изложение принципов “чистой” архитектуры, а также то, как их можно применить для построения архитектуры клиент-серверного приложения. Осталось показать, как это можно сделать на практике.
В качестве основы мы возьмем приложение для просмотра фильмов с прошлой лекции и переделаем его архитектуру согласно принципам “чистой” архитектуры.
В примере мы будем следовать идеям, которые изложил Фернандо Цехас в своей статье, и также разобьем приложение на 3 модуля: data, domain и presentation. При этом нужно помнить о том, что модуль domain является Java-модулем и не содержит классов Android.
Начнем со слоя данных. Напомним, как мы получали данные о фильмах на прошлом занятии:
mMoviesSubscription = ApiFactory.getMoviesService()
.popularMovies()
.map(MoviesResponse::getMovies)
.flatMap(movies -> {
Realm.getDefaultInstance().executeTransaction(realm -> {
realm.delete(Movie.class);
realm.insert(movies);
});
return Observable.just(movies);
})
.onErrorResumeNext(throwable -> {
Realm realm = Realm.getDefaultInstance();
RealmResults<Movie> results = realm.where(Movie.class).findAll();
return Observable.just(realm.copyFromRealm(results));
})
.doOnSubscribe(loadingView::showLoadingIndicator)
.doAfterTerminate(loadingView::hideLoadingIndicator)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(this::showMovies, throwable -> showError());
Этот код был расположен в Activity, и было очевидно, что он слишком сложный и громоздкий. К тому же в нем сразу выполняется множество операций: работа с сервисом Retrofit, кэширование данных, обработка ошибок и чтение данных из кэша. При этом по-хорошему в слое представления (а Activity является именно частью этого слоя) мы должны написать максимум такой код:
mMoviesSubscription = MoviesUseCase.popularMovies() .doOnSubscribe(loadingView::showLoadingIndicator) .doAfterTerminate(loadingView::hideLoadingIndicator) .subscribe(mView.showMovies, throwable -> mView.showError());
То есть во View мы должны писать только код, связанные с UI-логикой. А остальная часть запроса должна быть перенесена в другие слои, к примеру, в слой данных или слой бизнес-логики. Давайте реализуем такой подход и перенесем получение данных из Retrofit и работу с кэшированием в репозиторий.
Создаем интерфейс для репозитория в слое бизнес-логики (для взаимодействия через интерфейсы) и реализуем его в слое данных:
public class MoviesDataRepository implements MoviesRepository {
@Override
public Observable<List<Movie>> popularMovies() {
return ApiFactory.getMoviesService()
.popularMovies()
.map(MoviesResponse::getMovies)
.compose(new MoviesCacheTransformer())
.flatMap(Observable::from)
.map(new MoviesMapper())
.toList();
}
}
Здесь мы вначале получаем данные через сервис Retrofit, после добавляем обработку кэширования (сохранения и восстановления в случае ошибки) следующим образом:
public class MoviesCacheTransformer implements Observable.Transformer<List<Movie>, List<Movie>> {
@Override
public Observable<List<Movie>> call(Observable<List<Movie>> moviesObservable) {
return moviesObservable
.flatMap(mSaveFunc)
.onErrorResumeNext(mCacheErrorHandler);
}
}
Поля mSaveFunc и mCacheErrorHandler определяются в этом же классе, это обычные функции преобразования, которые для удобства были вынесены в отдельные поля:
private final Func1<List<Movie>, Observable<List<Movie>>> mSaveFunc = movies -> {
Realm.getDefaultInstance().executeTransaction(realm -> {
realm.delete(Movie.class);
realm.insert(movies);
});
return Observable.just(movies);
};
Так может выглядеть слой данных. Можно заметить, что мы не добавляем принципиально новых функций, а только гибко размещаем код по разным логическим модулям.
В слой данных также перемещается вся работа с сетью, к примеру, сервис Retrofit.
Теперь мы закончили слой данных и можем перейти к следующему слою – слою бизнес-логики. В нашем примере приложение не содержит никакой значимой бизнес-логики, оно только получает данные и отображает их. Поэтому слой бизнес-логики является очень небольшим и содержит только управление потоками:
public class MoviesUseCase {
private final MoviesRepository mRepository;
private final Observable.Transformer<List<Movie>, List<Movie>> mAsyncTransformer;
public MoviesUseCase(MoviesRepository repository,
Observable.Transformer<List<Movie>, List<Movie>> asyncTransformer) {
mRepository = repository;
mAsyncTransformer = asyncTransformer;
}
public Observable<List<Movie>> popularMovies() {
return mRepository.popularMovies()
.compose(mAsyncTransformer);
}
}
Слой бизнес-логики обращается к слою данных за получением данных с помощью объекта Repository.
Если бы в приложении была более сложная бизнес-логика, за нее отвечал бы этот класс. Тестировать его достаточно легко, нам нужно только передать ему такой экземпляр Repository, который нужен для конкретного теста (подмена окружения).
И остается последний слой – слой представления. На этом слое для разделения логики и непосредственно отображения UI используются различные паттерны, к примеру, MVP, MVVM, MVC. В силу особенностей системы Android паттерн MVP является наиболее удобным и часто применяемым.
Мы детально рассмотрим паттерн MVP в рамках следующей лекции, а пока сделаем небольшие пояснения относительно его принципов.
Когда мы видим код, написанный в рамках одного экрана (Activity / Fragment), мы можем легко сказать, какой код отвечает за непосредственное отображение данных пользователю, а какой код управляет логикой этого отображения. В этом и заключается суть паттерна MVP. Основным объектом является Presenter, который управляет View. Например, вот код Presenter-а, который хорошо иллюстрирует разделение функций:
public void init() {
mMoviesUseCase.popularMovies()
.doOnSubscribe(mMoviesView::showLoadingIndicator)
.doAfterTerminate(mMoviesView::hideLoadingIndicator)
.compose(mLifecycleHandler.load(R.id.movies_request_id))
.subscribe(mMoviesView::showMovies, throwable -> mMoviesView.showError());
}
Когда экран запускается, у Presenter-а вызывается метод init. В этом методе Presenter инициирует загрузку данных и во время всего этого процесса управляет экземпляром View: показывает и скрывает прогресс, отображает полученные данные и ошибки. При этом View не знает, когда и в зависимости от чего ей нужно выполнить ту или иную операцию с UI. Вместо этого она предоставляет интерфейс Presenter-у, который с помощью него и управляет UI-частью приложения. Такое разделение функций можно продемонстрировать с помощью таблицы:
| Presenter | View |
| Обращение к UseCase за получением данных | Нет действий |
| Показ прогресса при начале загрузки через метод showLoadingIndicator | Отображение диалога с ProgressBar |
| Скрытие прогресса после окончания загрузки | Скрытие диалога с ProgressBar
|
| Показ фильмов с помощью метода showMovies при получении данных | Передача списка фильмов в Adapter для RecyclerView |
| Отображение ошибки с помощью метода showError в случае ошибки | Показ текста с ошибкой и кнопкой обновления |
В этом и заключаются роли View и Presenter. В случае с Model все еще проще – это всего лишь классы моделей, которые передаются от Presenter к View.
Еще один важный вопрос заключается в обработке жизненного цикла экрана. Это относится к логике экрана, поэтому такой обработкой должен заниматься Presenter. Есть несколько вариантов того, как он может это делать. Первый – определить в Presenter методы жизненного цикла Activity / Fragment и вызывать их. Второй – передать специальный делегат, который будет заниматься обработкой жизненного цикла, как и сделано в примере:
public class MoviesPresenter {
private final MoviesView mMoviesView;
private final MoviesUseCase mMoviesUseCase;
private final LifecycleHandler mLifecycleHandler;
public MoviesPresenter(@NonNull MoviesView moviesView, @NonNull MoviesUseCase moviesUseCase,
@NonNull LifecycleHandler lifecycleHandler) {
mMoviesView = moviesView;
mMoviesUseCase = moviesUseCase;
mLifecycleHandler = lifecycleHandler;
}
public void init() {
mMoviesUseCase.popularMovies()
.doOnSubscribe(mMoviesView::showLoadingIndicator)
.doAfterTerminate(mMoviesView::hideLoadingIndicator)
.compose(mLifecycleHandler.load(R.id.movies_request_id))
.subscribe(mMoviesView::showMovies, throwable -> mMoviesView.showError());
}
}
Экземпляр LifecycleHandler, который передается в Presenter, является интерфейсом и позволяет обрабатывать события жизненного цикла и корректно сохранять состояния запроса.
Второй вариант предпочтительнее, так как он упрощает тестирование и позволяет изменять способ обработки жизненного цикла без изменения самих классов.
И последний вопрос, который нужно рассмотреть, – это вопрос тестирования. Presenter тестируется обычными тестами на JUnit с помощью Mockito. Все экземпляры View, делегата для обработки жизненного цикла подставляются в него так, как это нужно для тестирования. View, в качестве которого обычно выступает Activity или Fragment, тестируется с точки зрения UI с помощью таких средств как Espresso.
Таким образом, мы теперь можем грамотно строить архитектуру приложения, которая является модульной и позволяет тестировать приложение разными способами и на разных уровнях. Кроме того, мы умеем гибко выполнять и комбинировать запросы с помощью RxJava и обрабатывать ошибки. То есть, на текущий момент мы достигли всех целей, которые были обозначены в начале курса. Поэтому оставшиеся занятия будут посвящены вариантам улучшения рассмотренной архитектуры, а также тому, как именно писать тесты. Ведь пока мы говорили только о том, что тесты для такой архитектуры писать можно, но не говорили, как именно нужно это делать. А написание тестов также является серьезной задачей и требует детального рассмотрения.
Дополнительно – Google Agera
Мы познакомились и продолжаем работать с библиотекой RxJava как с основным инструментом для выполнения серверных запросов и обеспечения асинхронности. Но это не единственный возможный инструмент. Не так давно Google представил свою библиотеку с похожей парадигмой – Agera.
Эта библиотека во многом схожа с RxJava, но не нужно думать, что Google использует ее как основного конкурента для RxJava. Это исключительно внутренний продукт, который разработчики Google выложили в открытый доступ, и каждый разработчик может выбирать, что ему больше нравится.
Но чтобы можно было выбирать, нужно сначала познакомиться со всеми вариантами. Поэтому сейчас мы сделаем небольшое введение в Google Agera.
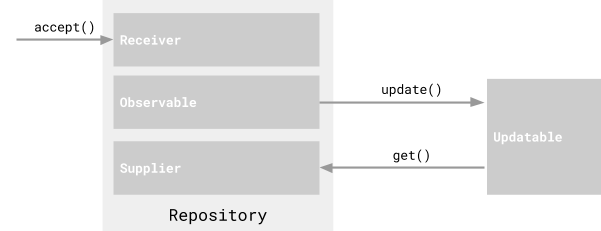
Библиотека Agera реализует парадигму реактивного программирования, которую мы рассматривали ранее. Она строится на 4 китах (или, точнее, на 4 интерфейсах):
- Observable – объект, за изменениями которого можно наблюдать и который хранит список объектов, наблюдающих за изменениями этого объекта.
- Updatable – наблюдатель за изменениями в Observable. Вместе этот и предыдущий объекты образуют стандартный паттерн наблюдатель.
- Supplier – объект, который предоставляет данные.
- Receiver – объект, который получает данные.
Такая схема выглядит весьма просто и логично. Посмотрим, как ее можно использовать на практике. Создадим поставщик данных (Supplier), за которым можно наблюдать, который сможет возвращать и получать данные. Это может выглядеть следующим образом:
private class HelloWorldSupplier implements Observable, Supplier<String>, Receiver<String> {
private final List<Updatable> mUpdatables = new ArrayList<>();
private String mValue;
@Override
public void addUpdatable(@NonNull Updatable updatable) {
mUpdatables.add(updatable);
}
@Override
public void removeUpdatable(@NonNull Updatable updatable) {
mUpdatables.remove(updatable);
}
@NonNull
@Override
public String get() {
return mValue;
}
@Override
public void accept(@NonNull String value) {
mValue = value;
// Notify the updatables that we have new data
for(Updatable updatable : mUpdatables) {
updatable.update();
}
}
}
И использовать этот поставщик данных можно следующим образом:
HelloWordSupplier supplier = new HelloWordSupplier();
Updatable updatable = () -> Log.i("Agera", supplier.get());
supplier.addUpdatable(updatable);
supplier.accept("Hello World!");
И это только приложение, которое выводит в лог Hello World! Даже с начальным количеством кода в RxJava было проще разобраться. Что здесь происходит? Во-первых, реализуется обычный паттерн наблюдатель (хранится определенное значение, при изменении которого подписчики уведомляются). Во-вторых, есть методы для получения значения и его изменения. И в-третьих, есть подписчики, которые получают результаты изменений. Итоговая схема такого взаимодействия выглядит следующим образом:
Несмотря на сложность, код примера полностью логичен и масштабируем. Однако это всего лишь основы, которые помогают понять, как работает Agera внутри. Разумеется, Agera обеспечивает более простые средства для разработчиков.
Поставщик данных, которые мы реализовали самостоятельно, схожим образом реализуется в наиболее важном элементе библиотеки Agera – Repository. Поэтому теперь нам достаточно написать всего лишь такой код:
MutableRepository<String> repository = Repositories.mutableRepository("Initial values");
Updatable updatable = () -> Log.i("Agera", repository.get());
repository.addUpdatable(updatable);
repository.accept("Hello World!");
Этот код почти аналогичен предыдущему, за исключением того, что Repository является потокобезопасным и у него более сложная логика уведомлений об изменениях.
Так зачем же это все может понадобиться и как использовать Agera для получения данных? Паттерн наблюдатель часто используется для организации клиент-серверного взаимодействия. К примеру, мы можем подписаться на изменения в репозитории и, когда данные в репозитории будут загружены, автоматически получить уведомления в подписчике.
И, как уже говорилось, библиотека Agera схожа с RxJava в том, что реализует реактивную парадигму. А мы уже убедились, насколько это удобно. Более того, Agera точно также позволяет управлять асинхронностью выполнения и преобразовывать данные в потоке.
Рассмотрим пример для получения списка фильмов с сервера с последующим их отображением:
mMoviesRepository = Repositories.repositoryWithInitialValue(Result.<List<Movie>>absent())
.observe()
.onUpdatesPerLoop()
.goTo(AsyncExecutor.EXECUTOR)
.getFrom(() -> {
try {
return ApiFactory.getMoviesService().popularMovies().execute().body();
} catch (IOException e) {
return new MoviesResponse();
}
})
.thenTransform(input -> Result.absentIfNull(input.getMovies()))
.compile();
Здесь создается экземпляр Repository, который будет отвечать за получение списка фильмов. Далее мы подписываемся на него в методе onResume и отписываемся в onPause:
@Override
protected void onResume() {
super.onResume();
mMoviesRepository.addUpdatable(this);
}
@Override
protected void onPause() {
mMoviesRepository.removeUpdatable(this);
super.onPause();
}
После этого, когда будут получены данные, будет вызван метод Update, в котором мы и обработаем результат и ошибки:
@Override
public void update() {
mMoviesRepository.get()
.ifSucceededSendTo(this::showMovies)
.ifFailedSendTo(value -> showError());
}
Кажется, что RxJava в плане удобства работы проще и понятнее, но однозначно сказать, что нужно использовать, конечно же, не получится. Нужно попробовать все варианты и выбрать из них наиболее удобный.
Таким образом, мы рассмотрели в общих чертах библиотеку Google Agera и поняли, как ее можно использовать на практике для построения приложения. Возможно, вы и не станете ее использовать, но в любом случае, это мощный инструмент, который стоит изучить.
Практика
1)Скачать Проект PopularMoviesClean
2)Нужно реализовать экран с отдельным фильмом и загрузить информацию о трейлерах и отзывах кинокритиков
3)Реализация должна следовать принципам Clean Architecture
4)Нужно обрабатывать события жизненного цикла
5)Требования можно посмотреть по ссылке http://goo.gl/EpF3N2
Практика 2
1) Скачать Проект PopularMoviesAgera
2)Нужно реализовать экран с отдельным фильмом и загрузить информацию о трейлерах и отзывах кинокритиков
3)Приложение должно использовать Google Agera в качестве основного инструмента для получения данных
4)Требования можно посмотреть по ссылке http://goo.gl/EpF3N2
Ссылки и полезные ресурсы
- Приложения из репозитория:
- PopularMoviesClean – пример приложения, написанного по Clean Architecture и практическое задание.
- PopularMoviesAgera – пример приложения, основанного на фреймворке Google Agera и практическое задание.
- Книга “Clean Code” от Роберта Мартина.
- Clean Architecture от Роберта Мартина.
- Статья про Clean Architecture в Android от Фернандо Цехаса и ее перевод на хабре.
- Пример от Фернандо Цехаса, реализующий принципы Clean Architecture, а также одна из интересных дискуссий.
- Доклад с Droidcon Moscow 2015 про MVP и Clean Architecture.
- Документация по Google Agera и вопрос про отношения с RxJava.
- Кодлаб по Google Agera.


