Третья лекция Курса по архитектуре клиент-серверных android-приложений, в которой мы познакомимся с RxJava и основными операторами, а также узнаем, как создавать Observable, преобразовывать потоки данных, работать с RxJava в Android и решать проблему Backpressure.
Ссылки на исходный код ваших решений вы можете оставлять в комментариях. Делитесь вашими решениями с сообществом, получайте обратную связь и конструктивную критику. Лучшие решения будут опубликованы на нашем канале и сайте fandroid.info с указанием авторства победителей!
Дополнительно – проблема Backpressure
[wpanchor id=»1″]
Введение
Сейчас мы знаем немало способов выполнять какую-то работу в фоновых потоках. Под работой здесь чаще всего понимаются серверные запросы. Но насколько все хорошо с этими способами? Нужно признать, что у них немало недостатков.
Во-первых, эти способы не гибкие. Допустим, нужно выполнить два запроса параллельно, а потом, дождавшись, когда оба завершат работу, выполнить третий запрос с использованием результатов предыдущих запросов. Если вы попробуете реализовать такую задачу с использованием лоадеров, то скорее всего у вас получится большое количество булевских флагов, полей для сохранения результата и много кода. К проблемам гибкости можно также отнести и то, что сложно хорошо реализовать периодическое обновление данных.
Во-вторых, неудобно обрабатывать ошибки. Опять же, в случае лоадеров мы можем вернуть только один результат. Конечно, можно использовать специальные классы, которые будут служить как для передачи данных, так и для передачи ошибок, но это неудобно.[wpanchor id=»2″]
Именно поэтому нам нужно рассмотреть другие возможности для выполнения сетевых запросов и для работы с данными. И в первую очередь такой возможностью является популярный фреймворк RxJava.
RxJava
Фреймворк RxJava позволяет использовать парадигму функционального реактивного программирования (FRP) в Android. Понять, что это значит, весьма непросто, поэтому требуется немало пояснений. Во-первых, слово функциональное означает то, что в FRP основным понятием являются функции и в этом эта парадигма схожа с обычным функциональным программированием. Конечно, в Android весьма затруднительно использовать полноценное функциональное программирование, но все же с помощью RxJava мы смещаем приоритет от объектов к функциям. Во-вторых, реактивное программирование означает программирование с асинхронными потоками данных. Проще всего это пояснить на практике: поток данных – это любой ваш запрос на сервер, данные из базы, да и обычный ввод данных от пользователя (если говорить совсем уж откровенно, то создать поток данных можно абсолютно из чего угодно), который чаще всего выполняется в фоновом потоке, то есть асинхронно. Если объединить два объяснения, то получим, что функциональное реактивное программирование – это программирование с асинхронными потоками данных, которыми можно манипулировать с помощью различных функций.
Определение звучит красиво, но только совсем непонятно, зачем это может понадобиться. Оказывается, еще как может. RxJava позволяет решить почти все проблемы, которые были озвучены во введении. В качестве основных преимуществ RxJava выделяются следующие:
- Обеспечение многопоточности. RxJava позволяет гибко управлять асинхронностью выполнения запросов, а также переключать выполнение операций в различные потоки. Кроме того, что немаловажно для Android, RxJava также позволяет легко обрабатывать результат в главном потоке приложения.
- Управление потоками данных. Это позволяет преобразовывать данные в потоке, применять операции к данным в потоке (к примеру, сохранять их данные из потока в базу), объединять несколько потоков в один, изменять поток в зависимости от результата другого и многое другое.
- Обработка ошибок. Это еще одно очень важное преимущество RxJava, которое позволяет обрабатывать различные ошибки, возникающее в потоке, повторять серверные запросы в случае ошибки и передавать ошибки подписчикам.
И самое приятное, что все преимущества выше достигаются буквально за пару строчек кода!
Использовать RxJava непросто, а использовать ее правильно еще сложнее, и это требует достаточно долгого изучения. RxJava – это очень большой фреймворк, чтобы правильно работать с ним (и в частности с парадигмой функционального реактивного программирования), нужно очень много изучать и практиковаться. RxJava достойна отдельного курса, по ней существует огромное количество статей, и их число увеличивается с каждым днем. По RxJava написана уже не одна книга, поэтому нельзя надеяться, что можно хорошо изучить этот фреймворк в рамках одной лекции. Но мы постараемся рассмотреть основные возможности RxJava и то, как ее можно применить для Android.
Мы немного рассмотрели суть RxJava и функционального реактивного программирования, но чтобы продвинуться дальше, нам нужно знать основные элементы этого фреймворка, к примеру, что подразумевается под потоком данных и как его создать, что такое подписчик и как его использовать и так далее.
RxJava в качестве своей основы использует паттерн Observer. Как выглядит этот паттерн в классическом виде? Основными сущностями в нем являются объект, значение которого может изменяться, и подписчик, который может подписаться на эти изменения (каждый раз при изменении значения объекта у подписчика будет вызван определенный метод). Схематично это можно представить следующим образом: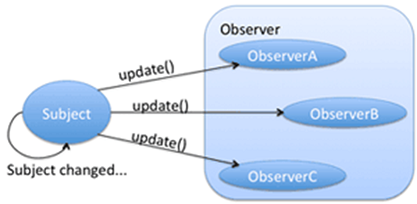
Суть RxJava почти такая же, только вместо одного объекта подписчики используют целый поток данных. Подписчик может подписаться на поток данных, и тогда он будет получать информацию о каждом новом элементе в потоке, о произошедших ошибках, а также о завершении потока.
Тогда схема для RxJava будет такой:
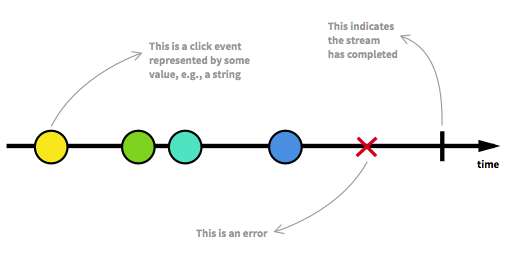
С подписчиком все более менее понятно, а что же такое поток данных? Поток данных – это всего лишь набор каких-то элементов (необязательно конечный), которые передаются подписчику. В качестве потока данных могут выступать как простые объекты и последовательности, так и бесконечные, последовательности и различные события, к примеру, ввод данных.
Рассмотрим один из примеров, который поможет понять, где именно встречаются потоки данных и как в работе с ними может помочь RxJava. Допустим, стоит задача искать людей с определенным именем, когда пользователь вводит текст в поле поиска. Ее можно решить следующими простыми строчками кода:
editText.observeChanges()
.debounce(500, TimeUnit.MILLISECONDS)
.map(String::toLowerCase)
.flatMap(this::findPerson)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(person -> {}, throwable -> {});
Мы детально разберем каждый оператор далее, но пока только объясним, что происходит в коде, чтобы понять, насколько мощным инструментом является RxJava.
Во-первых, мы превращаем ввод текста в поток данных, за которым мы будем наблюдать. Наш поток может выглядеть, например, так: “J”, “Jo”, “Joh”, “John”, … Это поток данных.
Как уже говорилось, мы можем управлять данными в потоке. Допустим, мы не хотим, чтобы запрос выполнялся слишком часто. Для этого используется оператор debounce, который передает данные подписчику только тогда, когда между поступающими данным в потоке произошла пауза (500 миллисекунд в нашем примере). Тогда, к примеру, наш поток данных может стать таким: “J”, “John”, …
Далее с помощью оператора map все данные в потоке превращаются в строки нижнего регистра. После этого поток выглядит следующим образом: “j”, “john”, …[wpanchor id=»3″]
И после этого выполняется запрос на сервер для поиска человека с таким именем. В результате наш поток данных из строк превращается в поток данных из людей и может выглядеть вот так:
Person{name=”James”, age=25}, Person{name=”John”, age=17}.
И более того, все это выполняется в фоновом потоке, а результат возвращается в главный поток приложения. Поразительный результат за 7 строчек кода!
Введение в RxJava
После краткого объяснения сути RxJava перейдем непосредственно к коду и способам работы с этим фреймворком. В RxJava в качестве потока данных выступает класс Observable. И как уже говорилось выше, поток данных может быть асинхронным, а также над каждым элементом в потоке или даже над всем потоком могут выполняться различные операции преобразования.
Рассмотрим простейший способ создания потока данных (Observable) из нескольких элементов с помощью метода just:
Observable<Integer> observable = Observable.just(1, 2, 4);
Все крайне просто. Мы создали поток данных из 3 элементов. Теперь осталось только подписаться на него и, к примеру, вывести в лог все элементы:
observable.subscribe(new Observer<Integer>() {
@Override
public void onCompleted() {
// do nothing
}
@Override
public void onError(Throwable e) {
// do nothing
}
@Override
public void onNext(Integer integer) {
Log.i(TAG, String.valueOf(integer));
}
});
Сложно не заметить, что сейчас все резко перестало быть простым и компактным. Но это мы исправим, а пока все же поясним, что здесь написано. Как видно, в качестве подписчика на поток выступает реализация интерфейса Observer. В нем определено 3 метода. Метод onNext вызывается, когда подписчику передается следующий элемент из потока. Методы onError и onCompleted вызываются, когда в потоке данных происходит ошибка и когда поток данных завершается соответственно.
Теперь давайте изменим наш код, чтобы он стал короче и приятнее для чтения. Видно, что мы никак не используем методы onError и onCompleted, поэтому они нам не нужны. К счастью, у метода subscribe есть множество разных форм, и они позволяют использовать только нужные методы. К примеру, таким образом можно только обрабатывать вызов onNext:
Observable<Integer> observable = Observable.just(1, 2, 4); observable.subscribe(integer -> Log.i(TAG, String.valueOf(integer)));
А вот этот код уже сильно короче и понятнее. И мы к тому же не лишаемся возможности обрабатывать ошибки, нужно только вторым параметром передать этот обработчик:
observable.subscribe(
integer -> Log.i(TAG, String.valueOf(integer)),
throwable -> {/*handle error*/});
Разумеется, ситуация с onComplete полностью аналогична.
А вот теперь очень интересный и справедливый вопрос. Это, конечно, круто, что мы использовали потоки данных, подписчики и мощь RxJava, но мы же только вывели данные в лог. Я могу сделать это немного проще:
int[] items = new int[]{1, 2, 4};
for (int value : items) {
Log.i(TAG, String.valueOf(value));
}
И это, конечно, правильно. Чтобы показать превосходство RxJava, давайте устроим небольшое соревнование, где каждая задача будет реализовываться как с помощью RxJava, так и с помощью циклов.
Задача 1: Дан набор степеней двойки от 1 до 64 включительно, каждый их них нужно вывести в лог как в предыдущем примере. При этом вызов String.valueOf смотрится некрасиво, нужно переделать так, чтобы данные в потоке / массиве превращались в строки.
//RxJava
Observable.just(1, 2, 4, 8, 16, 32, 64)
.map(String::valueOf)
.subscribe(value -> Log.i(TAG, value));
//For
int[] items = new int[]{1, 2, 4, 8, 16, 32, 64};
for (int value : items) {
String s = String.valueOf(value);
Log.i(TAG, s);
}
Какого-то заметного преимущества RxJava тут не заметно. Так что идем дальше.
Задача 2: Нужно изменить данные так, чтобы в лог попали только числа от 13 и выше:
//RxJava
Observable.just(1, 2, 4, 8, 16, 32, 64)
.filter(integer -> integer >= 13)
.map(String::valueOf)
.subscribe(value -> Log.i(TAG, value));
//For
int[] items = new int[]{1, 2, 4, 8, 16, 32, 64};
for (int value : items) {
if (value >= 13) {
String s = String.valueOf(value);
Log.i(TAG, s);
}
}
И хоть заметной разницы в количестве кода нет, нужно сказать, что код с RxJava выглядит чище, логичнее и понятнее. Давайте добьем способы работы через циклы следующей задачей.
Задача 3: все операции над данными должны выполняться в фоновом потоке, а вывод данных в лог – в главном потоке приложения:
//RxJava
Observable.just(1, 2, 4, 8, 16, 32, 64)
.filter(integer -> integer >= 13)
.map(String::valueOf)
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(value -> Log.i(TAG, value));
//For
EXECUTOR.execute(() -> {
int[] items = new int[]{1, 2, 4, 8, 16, 32, 64};
for (int value : items) {
if (value >= 13) {
String s = String.valueOf(value);
HANDLER.post(() -> Log.i(TAG, s));
}
}
});
Решение предыдущей задачи в 2 строки – вот она, истинная мощь RxJava при работе с потоками (при этом код остается в разы чище и понятнее). А при использовании циклов нам пришлось создавать Executor для работы в фоне и Handler для передачи данные в главный поток приложения.[wpanchor id=»4″]
Даже такие игрушечные примеры показывают то, что у RxJava есть преимущества, которыми нужно пользоваться. Хотя, конечно, если говорить прямо, то RxJava и циклы – это вещи, которые нельзя сравнивать, так как это совершенно разные парадигмы.
Давайте продолжим знакомство с RxJava и ее различными операторами. И начнем с рассмотрения способов создания потоков данных.
Создание Observable
Мы уже видели использование метода just для создания Observable. Примерно аналогичным является метод from, который позволяет создать поток данных из списка элементов:
List<Integer> values = new ArrayList<>(); values.add(5); values.add(10); values.add(15); values.add(20); return Observable.from(values);
На самом деле все методы создания потоков данных в итоге вызывают стандартный метод Observable.create. Поэтому рассмотрим и этот способ. По сути, при использовании такого подхода мы сами управляем тем, какие данные передавать подписчику, и сами вызываем методы onNext, onError и onCompleted. Простой пример создания Observable через create:
@NonNull
public static Observable<Integer> observableWithCreate() {
return Observable.create(subscriber -> {
subscriber.onNext(5);
subscriber.onNext(10);
try {
//stub long-running operation
Thread.sleep(300);
} catch (InterruptedException e) {
subscriber.onError(e);
return;
}
subscriber.onNext(15);
subscriber.onCompleted();
});
}
Как видно в примере, мы вручную передаем данные в подписчик. При этом такой поток данных будет отдан каждому подписчику, который подпишется на созданный Observable.
Использовать метод create напрямую разработчикам не рекомендуется. Немного скажем об этом сейчас, а подробнее будет в дополнительной лекции по проблеме Backpressure. В этой же лекции будут рассмотрены и другие способы создания Observable.
Чем же неудобен метод create? Во-первых, вам нужно корректно обрабатывать все потенциальные ошибки и передавать их в подписчик самостоятельно. Во-вторых, нужно всегда следить за тем, что подписчик еще подписан на поток данных. К примеру, рассмотрим код подписки на Observable, который был описан выше:
Subscription subscription = RxJavaCreate.observableWithCreate() .subscribeOn(Schedulers.newThread()) .subscribe(System.out::println); subscription.unsubscribe();
В этом коде подписчик подписывается на получение данных и сразу от них отписывается. А код Observable ждет 300мс перед тем, как передать подписчику последний элемент, и в момент передачи подписчик уже отписался от получения данных. Поэтому происходит ошибка. Поэтому код в методе create нужно модифицировать, добавив проверку на то, что подписчику еще нужны данные из потока:
@NonNull
public static Observable<Integer> observableWithCreate() {
return Observable.create(subscriber -> {
subscriber.onNext(5);
subscriber.onNext(10);
try {
//stub long-running operation
Thread.sleep(300);
} catch (InterruptedException e) {
subscriber.onError(e);
return;
}
if (!subscriber.isUnsubscribed()) {
subscriber.onNext(15);
}
subscriber.onCompleted();
});
}
При этом такую проверку нужно добавлять перед каждым вызовом onNext, onError и onCompleted (здесь это опущено для удобства), что неудобно и часто приводит к ошибкам. Поэтому метод create использовать не нужно.
Кроме непосредственного создания потока данных, важно знать, как выполнять операции над данными в фоновом потоке, а также как обрабатывать результат в определенном потоке. Для этого служат операторы subscribeOn и observeOn, в которых очень часто путаются разработчики, только начинающие свое знакомство с RxJava.
Метод subscribeOn служит для указания потока, в котором выполняется код для создания данных в Observable. Если смотреть с точки зрения кода, то код в методе call в интерфейсе onSubscribe будет выполнен в том потоке, который был передан в метод subscribeOn. Метод observeOn указывает поток, в котором данные должны обрабатываться подписчиком. Можно запоминать так, что подписчик – это наблюдатель (observer) и вы указываете, где именно ему нужно наблюдать – метод observeOn. А оставшийся метод служит для указания, где должен работать поток данных.
Не совсем корректно говорить, что в методах observeOn и subscribeOn мы указываем потоки, нет – мы передаем в них экземпляры Scheduler, которые в том числе берут на себя работу по планированию задач. Можно создавать свои Scheduler, но обычно хватает использования стандартных:
- io() – выполнение задач, которые не сильно нагружают процессор, но являются долгими. Это, к примеру, обращения к серверу или к базе данных. Размер пула потоков не ограничен.
- computation() – выполнение вычислительных задач. Размер этого пула эквивалентен количеству ядер процессора.
- newThread() – создает новый поток для каждой задачи.
- immediate() – выполнение задачи в том же потоке, откуда вызывается Observable. Чаще всего его используют для тестирования.
Кроме того, в библиотеке RxAndroid есть AndroidSchedulers.mainThread(), который переносит выполнение кода подписчика в главный поток.[wpanchor id=»5″]
Исходя из объяснений понятно, что чаще всего вы будете использовать Schedulers.io() для запросов к серверу и базе данных, а в AndroidSchedulers.mainThread() будете обрабатывать результат. Поэтому код для большинства Observable будет выглядеть вот так:
return Observable.just(1) .subscribeOn(Schedulers.io()) .observeOn(AndroidSchedulers.mainThread());
Основные операторы
Рассмотрим основные операторы, которые вы можете использовать для преобразования данных в потоке. Каждый из этих операторов принимает в качестве значения какую-то функцию – в этом и реализуется парадигма функционального реактивного программирования.
Какие-то из операторов мы уже видели. Разумеется, это в первую очередь оператор map, который преобразовывает элемент в потоке в любой другой элемент. Его работу можно наглядно представлять с помощью следующей схемы:
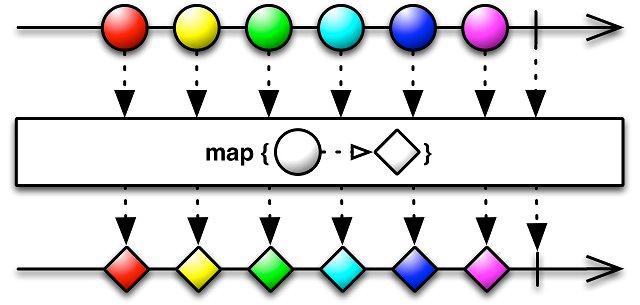
Мы уже применяли оператор map ранее для преобразования числа в строки. Это не единственное применение, вы можете преобразовывать что угодно во что угодно, главное, чтобы это нужно было по логике вашего приложения.
Нужно сказать еще одно замечание: если для преобразования одного объекта в другой требуется несколько операций, лучше использовать несколько операторов map, чем писать несколько операций в одном операторе. Это сильно улучшит читаемость вашего кода. То есть вместо такого кода:
return observable
.map(integer -> {
int value = integer * 2;
String text = String.valueOf(value);
return text.hashCode();
});
Лучше использовать такой:
return observable
.map(integer -> integer * 2)
.map(String::valueOf)
.map(String::hashCode);
Второй вариант кода не является единственно правильным или более быстрым, но он проще для понимания и лучше согласуется с принципами функционального реактивного программирования.
Большинство из этих операторов либо просты, либо не очень часто употребляются, поэтому для следующих операторов мы приведем только краткое описание со схемой и без примеров кода.
Также популярным является оператор filter, который оставляет в потоке только данные, удовлетворяющие переданному в качестве параметра условию.
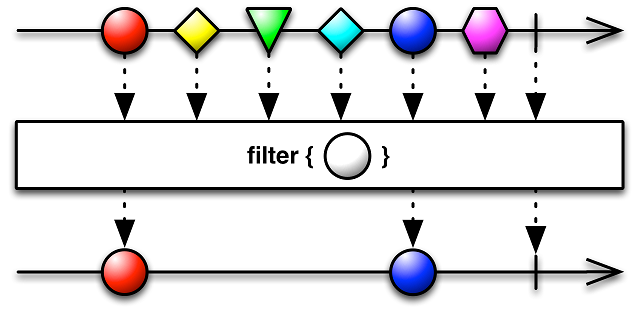
Также есть и другие методы, предназначенные для фильтрации данных в потоке, к примеру, skip, take, first и другие:
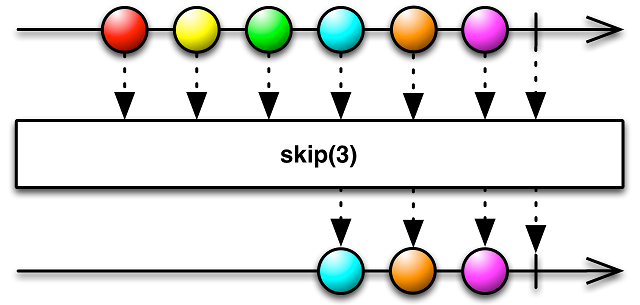
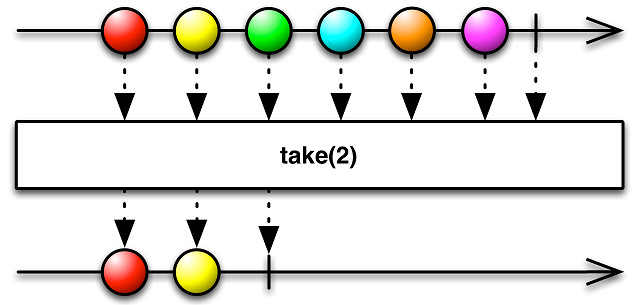
Существует еще очень большое количество различных операторов, полное описание и схему работы которых можно найти в документации, поэтому смысла перечислять их здесь нет.
В классе Observable определено много стандартных и полезных операторов. Но что делать, если вы хотите каким-то образом преобразовать Observable, а стандартные операторы позволяют сделать это за несколько действий или лишними строчками кода? К примеру, для каждого сетевого запроса вы наверняка будете писать следующий код для управления потоками:
return Observable.just(1) .subscribeOn(Schedulers.io()) .observeOn(AndroidSchedulers.mainThread());
И это, подчеркнем еще раз, будет для каждого запроса. Было бы логично, если бы могли использовать свой оператор для этой задачи. Для таких целей служит интерфейс Transformer. Создадим свой трансформер для потока данных:[wpanchor id=»6″]
public class AsyncTransformer<T> implements Observable.Transformer<T, T> {
@Override
public Observable<T> call(Observable<T> observable) {
return observable
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread());
}
}
И теперь мы можем использовать этот трансформер универсальным образом:
@NonNull
public static Observable<Integer> async() {
return Observable.just(1)
.compose(new AsyncTransformer<>());
}
Преобразование потоков данных
Кроме непосредственно преобразования данных в потоке, вы можете управлять и самим потоком: к примеру, при наступлении определенного условия мы можете заменить один поток на другой, или же объединить выполнение нескольких потоков вместе или последовательно. Для этого есть другая большая группа операторов.
Чтобы выполнить последовательно несколько Observable, можно использовать метод concat, схема которого выглядит следующим образом:
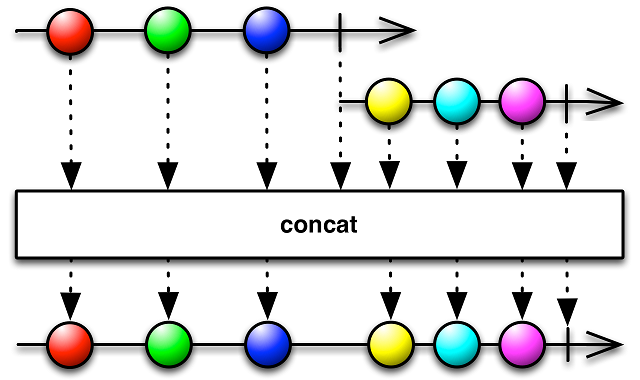
И в коде этот метод можно использовать примерно так:
Observable<Integer> first = Observable.just(1, 4, 8);
Observable<Integer> second = Observable.just(2, 6, 9);
Observable<Integer> third = Observable.just("Red", "Hello").map(String::length);
return Observable.concat(first, second, third);
Аналогично, если вам нужно выполнить несколько Observable не последовательно, а параллельно (что часто бывает нужно, чтобы ускорить загрузку при выполнении нескольких запросов), то вы можете использовать оператор merge:
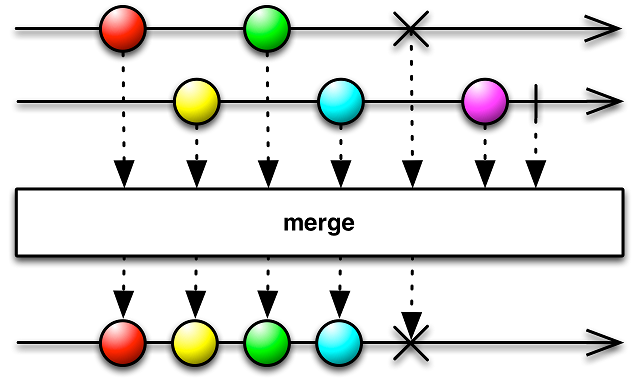
При этом порядок поступления элементов не определен. Этот метод используется аналогично методу concat:
Observable<Integer> first = Observable.just(1, 4, 8);
Observable<Integer> second = Observable.just(2, 6, 9);
Observable<Integer> third = Observable.just("Red", "Hello").map(String::length);
return Observable.merge(first, second, third);
Нужно также сказать, что и метод concat, и метод merge требуют, чтобы данные в Observable были одного типа, что не всегда удобно.
Есть и более интересный метод для параллельного выполнения запросов, который к тому же потом позволяет обработать результаты всех потоков вместе и преобразовать данные нужным образом. Это метод zip, который принимает на вход список Observable, которые будут выполняться параллельно, а также функцию для преобразования данных из всех запросов:
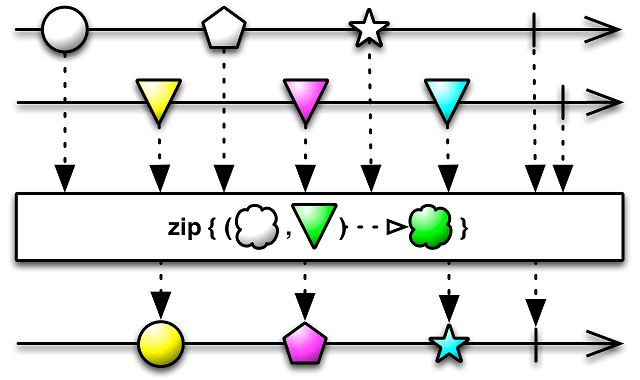
И его использование в коде:
Observable<String> names = Observable.just("John", "Jack");
Observable<Integer> ages = Observable.just(28, 17);
return Observable.zip(names, ages, Person::new);
В этом примере создается один поток данных из имен людей, еще один из возрастов, после этого эти потоки выполняются параллельно и преобразовываются в поток людей, используя данные из обоих исходных потоков.
Но, вероятно, одним из самых популярных операторов является оператор flatMap. Он похож на оператор map, но с небольшим исключением. Если map предназначен для преобразования объекта в объект, то flatMap каждый объект в потоке данных преобразует в Observable, а потом соединяет все получившиеся потоки данных. Схема этого оператора выглядит следующим образом:
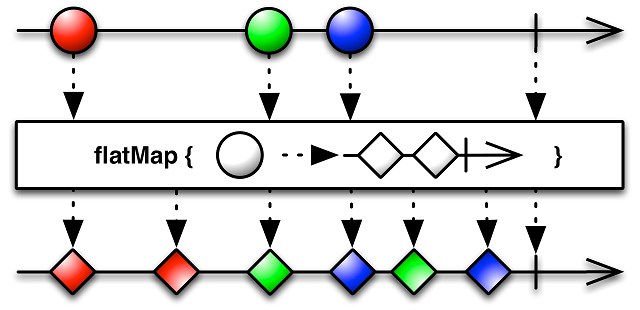
Оператор flatMap часто используется для различных преобразований над потоками, к примеру, чтобы вернуть ошибку, в случае если пришли некорректные данные или что-то пошло не так, как задумывалось. Мы и сами использовали такой пример в прошлой лекции, когда обрабатывали изменение статуса запроса. Сейчас мы можем разобрать этот фрагмент кода с большим пониманием:
RxSQLite.get().querySingle(RequestTable.TABLE, where)
.compose(RxSchedulers.async())
.flatMap(request -> {
if (request.getStatus() == RequestStatus.IN_PROGRESS) {
mLoadingView.showLoadingIndicator();
return Observable.empty();
} else if (request.getStatus() == RequestStatus.ERROR) {
return Observable.error(new IOException(request.getError()));
}
return RxSQLite.get().querySingle(CityTable.TABLE).compose(RxSchedulers.async());
})
В первую очередь нужно заметить, что мы получаем только один элемент в Observable со статусами, и на основании него изменяем поток данных.
Во-первых, если статус запроса IN_PROGRESS, то нам больше не нужно продолжать выполнение запроса, поэтому мы возвращаем пустой поток данных. Во-вторых, если произошла ошибка (вот это и есть пример, когда никакого явного Exception не возникает, однако логически произошла ошибка), мы возвращаем Observable с ошибкой. И наконец, если запрос выполнился успешно, то мы меняем поток данных со статусом запрос на поток данных с прогнозом погоды. Здесь оператор flatMap демонстрирует всю свою мощь.
Это, вероятно, основные и наиболее часто используемые операторы. Однако снова нужно сказать, что существует еще очень большое количество различных операторов, каждый из которых хорошо подходит для определенного случая.



Для .just IDEA предлагает это
https://drive.google.com/open?id=17vg1_gYsEl3x-Q_A0MACQra9Jor8SWMs
https://drive.google.com/open?id=1eaLJDC91J7jD2hKQjcjaBzer1krEPaNI
а для .subscribe это
https://drive.google.com/open?id=19txTx0upJYBAHCWRNvL0A-xwM1YXOtIE
https://drive.google.com/open?id=1C2Klwj1fXkDVu3mbfeKprkMqqUpKUXjM
Проверьте импорт — не тот класс Observable
Виталий, подскажите почему два метода(.just и .subscribe) в коде: https://drive.google.com/open?id=1FWK7_HLzuMzu4vjABJb_g-Kkx2S3TJ3a
подсвечиваются красным? Какие пакеты ещё нужно подключить?
Наведите на красные и нажмите Alt+Enter, посмотрите, что предлагает среда разработки